By Emily Bell and M. H. Beals
Just as the nineteenth-century newspaper was a messy object, filled with an ever-changing mix of material in an innumerable number of amorphous layouts, working with the structures of digitised newspapers is no different. While a user approaching a digitised newspaper collection through a glossy web interface and inputting keywords might not realise it, there are decades of decision-making processes still influencing what exactly it’s possible for that user to search for, and what they will find.[i] And if you’ve ever wondered why there isn’t one enormous search engine for newspapers and periodicals that aggregates global collections and makes them available in one place… well, this blog post will start to introduce the scale of the problem.
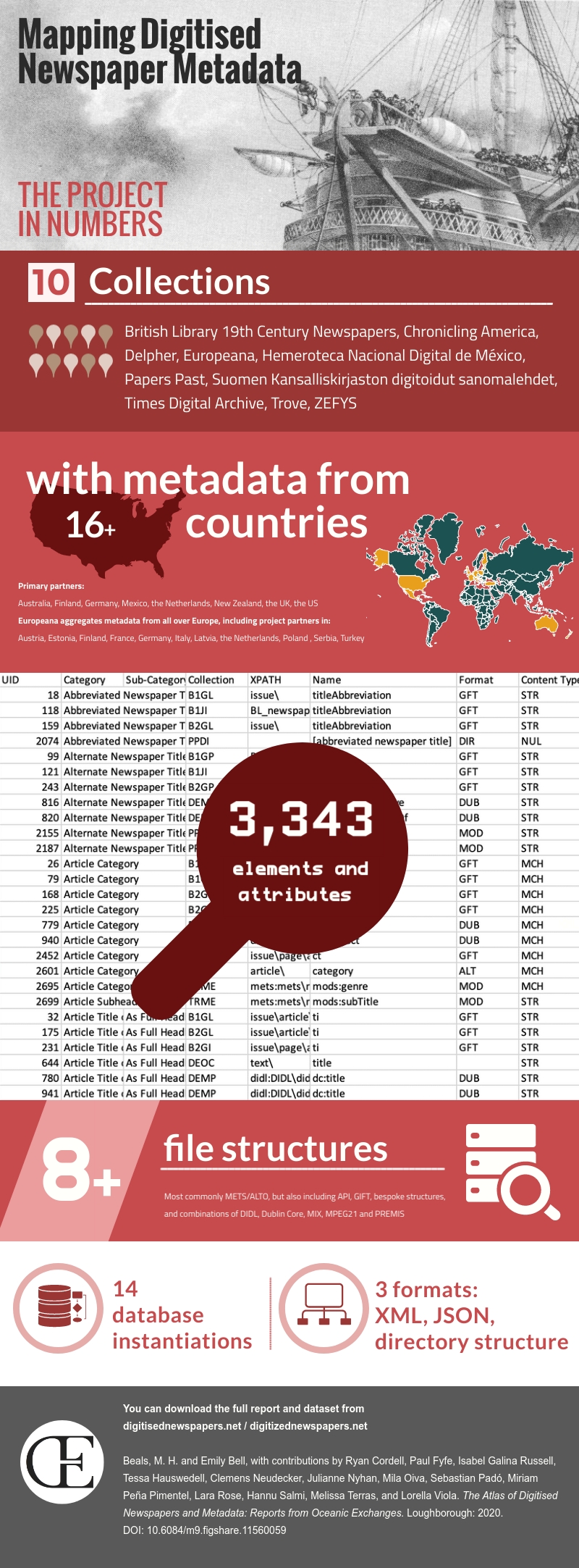
In January 2020, the ‘Oceanic Exchanges: Tracing Global Information Networks in Historical Newspaper Repositories, 1840-1914’ project, an AHRC/ESRC-funded ‘Digging into Data’ project that brought together a consortium of cultural historians, computational linguistics, literary scholars, digital curators, humanists, and computer scientists, launched a new resource for periodicals scholars (and anyone working with digitised newspapers): the Atlas of Digitised Newspapers and Metadata.[ii]
Working closely with the British Library 19th Century Newspapers, Chronicling America, Delpher, Europeana, the National Digital Newspaper Archive of Mexico, Papers Past, the National Library of Finland, the Times Digital Archive, Trove and ZEFYS, the project aimed to gain a clearer understanding of the ways these collections were built, both in terms of the institutional decision-making (i.e. selection decisions, funding and so on) and the metadata structure of newspapers within the collections.
Each of the databases contains a (theoretically) standardised collection of data, metadata, and images; however, the precise nature and nuance of the data is often occluded by the processes that encoded it. For example, if you’re looking for headlines only (as opposed to titles), you need a distinction that simply isn’t there. No true universal standard has been implemented, or even proposed, to facilitate cross-database analysis, encouraging digital research to remain within those existing institutional or commercial silos.
Optical Character Recognition and Optical Layout Recognition (also known as document layout analysis) also don’t currently allow for any sense of how the elements they analyse might change over time. Titles versus headlines is a good example. Headlines weren’t common in the UK until at least the 1870s, though they were introduced earlier in the US. Once headlines come in, it’s much easier to identify them as bigger blocks on the page (a spatial feature as much as a semantic one) but there is a large amount of variation between countries and even individual titles.
What we’re essentially pushing for is historically informed metadata that takes into account that the newspaper changed, and is still changing. This is to prevent an oversimplification that technology sometimes encourages: for example, most archives only digitise one newspaper edition per day, so those researching morning, afternoon and evening editions will find that many databases simply don’t have them.

Our open access report draws on ontologies of the file formats and ontologies and taxonomies of the newspaper itself, digitisation guidelines, the libraries’ websites, scholarly literature, grey literature (including digitisation strategies and annual reports), interviews with staff conducted in 2018, some shrewd use of rumours about institutional decision-making, and retro-engineering we’ve done ourselves. It offers abbreviated histories of the ten newspaper databases, including the chronology of their development, a discussion of each one’s aims and offerings, and a report on its current status and availability.
We tried to map all of the metadata fields – over 3300 different lines – directly, to find the same data in the different databases. This raised ontological issues not only in developing hierarchies and links between the fields of the various databases, but in understanding the vocabulary employed to describe elements and characteristics of the physical newspaper as well. In order to decide the structure, you need to consider the hierarchy of the newspaper. For example, is an article a smaller unit than a column? Or is a column a unit within an article (see fig. 2)? Does that remain the same throughout the nineteenth century and across different periodical types? Is a supplement part of an issue, or is it separate?

What we found was that it isn’t possible to reconcile these problems without falling into the trap of trying to create our own standard, and digitisers and researchers recognise that actually the messiness is inherent in the newspaper as a complex and evolving form, rather than it simply being a problem of messy metadata. Simple concepts like “title”, “publisher” and “article” became very complicated, very quickly – for example, was it a standardised title, or the title as printed on the physical object, or a variant title? Did it include the subtitle and/or motto? Was the “article” the document type or the genre (i.e. in contrast to classified adverts and images?). The heart of the report is a newspaper glossary that takes this very technical detail about digitised newspapers and brings it into conversation with researchers and press history. This is to allow people to understand a) how the term is being used in different ways by different groups and b) to help people map the type of information they really want with the data that is available in these collections.
The Atlas is (we hope) a first step in a multidisciplinary conversation, and one with a primarily Anglophone focus. We’re now hoping to encourage new tools and approaches to collections using our dataset, and we’ve opened the Atlas to contributors. We hope RSVP members will explore it, and we’d be pleased to hear any feedback about how it might be used and expanded.
Download the Atlas:
Beals, M. H. and Emily Bell, with contributions by Ryan Cordell, Paul Fyfe, Isabel Galina Russell, Tessa Hauswedell, Clemens Neudecker, Julianne Nyhan, Mila Oiva, Sebastian Padó, Miriam Peña Pimentel, Lara Rose, Hannu Salmi, Melissa Terras, and Lorella Viola. The Atlas of Digitised Newspapers and Metadata: Reports from Oceanic Exchanges. Loughborough: 2020. DOI:10.6084/m9.figshare.11560059.
[i] Tessa Hauswedell, Julianne Nyhan, M. H. Beals, Melissa Terras and Emily Bell. ‘Of global reach yet of situated contexts: an examination of the implicit and explicit selection criteria that shape digital archives of historical newspapers.’ Arch Sci (2020). https://doi.org/10.1007/s10502-020-09332-1.
[ii] M. H. Beals and Emily Bell, with contributions by Ryan Cordell, Paul Fyfe, Isabel Galina Russell, Tessa Hauswedell, Clemens Neudecker, Julianne Nyhan, Mila Oiva, Sebastian Padó, Miriam Peña Pimentel, Lara Rose, Hannu Salmi, Melissa Terras, and Lorella Viola. The Atlas of Digitised Newspapers and Metadata: Reports from Oceanic Exchanges. Loughborough: 2020. DOI:10.6084/m9.figshare.11560059.