Amelia Joulain-Jay is a PhD candidate in History/Linguistics at Lancaster University. For her PhD project, she has been exploring the promises and challenges involved in using corpus linguistics to derive historical insights from large amounts of digitised historical texts. She was awarded the 2016 Gale Dissertation Research Fellowship in Nineteenth-Century Media for this work. She will be delighted to answer (to the best of her abilities) any queries you may have about using corpus linguistics for your research on c19th newspapers.
You can contact her on Twitter via @joulain_jay or email her at a.t.joulain@lancaster.ac.uk.
Corpus Linguistics, and why you might want to use it, despite what (you think) you know about it
As part of the Spatial Humanities project at Lancaster University, and in collaboration with the Centre for Corpus Approaches to Social Sciences, the central aim of my PhD research project is to investigate the potential of corpus linguistics to allow for the exploration of spatial patterns in large amounts of digitised historical texts. Since I come from a Sociology/Linguistics background, my personal aim since the start of my PhD journey has been to try and understand what historical scholarship practices look like, what kinds of questions historians are interested in (whether they are presently being asked or not), how historians may benefit from using corpus linguistics, and also what challenges historians might encounter when trying to take advantage of corpus linguistics’ affordances. I don’t think I can over-stress how helpful coming to the RSVP conferences has been in this respect, and how grateful I am to the welcoming and helpful community of scholars I have encountered there.
I have chosen to write this post as an introduction to corpus linguistics for several reasons. First, on many counts RSVP members have asked me to explain to them what corpus linguistics consists of; I hope this post begins to answer that question. Second, I have sometimes encountered a reluctance to consider computerised text analysis methods. This reluctance is understandable and should be taken seriously. There are indeed very real challenges to working with computers in the Humanities and it is worth considering them. Ultimately, I hope to help bring corpus linguistics to the attention of those scholars who may find it useful.
The Humanities unavoidably involve messy data and the messy, fluid, categories which we try to apply to them. Computers on the other hand are all about known quantities and a lack of ambiguity. So why use computers in the Humanities? Computers are bad at what humans are good at: understanding. But they are also good at what humans are bad at: performing large and accurate calculations at remarkable speed. Generating historical insight cannot be done at the press of a button, but computers can assist us in manipulating the large amounts of data which are relevant to the questions we care about.
The most fundamental tool in corpus linguistics – the area of linguistics devoted to developing tools and methods to facilitate the quantitative and qualitative analysis of large amounts of text – is the concordance: a method which has been in use for centuries. A concordance is simply a list of occurrences of a word (or expression) of interest, accompanied by some limited context (see figure 1). Drawing up such a concordance manually is a very lengthy process, which can occupy years of an individual’s life. In contrast, once the data has been prepared in certain ways, specialised computer-based corpus linguistic tools can draw up such a concordance within a few seconds, even for tens of thousands of lines of text drawn from a database containing millions of words.[1] For just this simple feat, computers are invaluable for the historian. But why use corpus linguistics tools? After all, all historical digital collections come with interfaces which offer searchability through queries of some sort.

The answer to this question is simple: design. Corpus linguistic tools have been developed for linguists, who care about language and (linguistic) context, so the tools make it easy to switch between a concordance and lengthier sections of text around a particular concordance line (see figure 2). This is definitely faster and more practical than locating the correct page in the correct paper volume; it is also more useful than the format of results offered by most commercial database interfaces which assume that the user will be consulting results one at a time, with no simple way to relate results to each other (in the form of a concordance) or repeatedly switch from the results lists to the text itself. [2]

One of the most central concepts of corpus linguistics is collocation. The term has been defined in many different ways but these ultimately all refer to an observation about language: some words have a tendency to occur in proximity to other words. When we read concordances, we notice that certain words tend to occur together; these kinds of patterns often become precisely what is interesting about the texts we are looking at, and what we want to trace and analyse in a body of text. ‘What terms are used to describe this group of people, this location, this idea?’: this kind of question occurs in many different research contexts. Identifying words which frequently occur close to a word of interest is hence a useful endeavour, and a natural next step when working with a concordance. This can be done in an ad hoc matter whilst doing close reading; it can also be done more rigorously whilst close reading – this will involve keeping track of how often words occur.
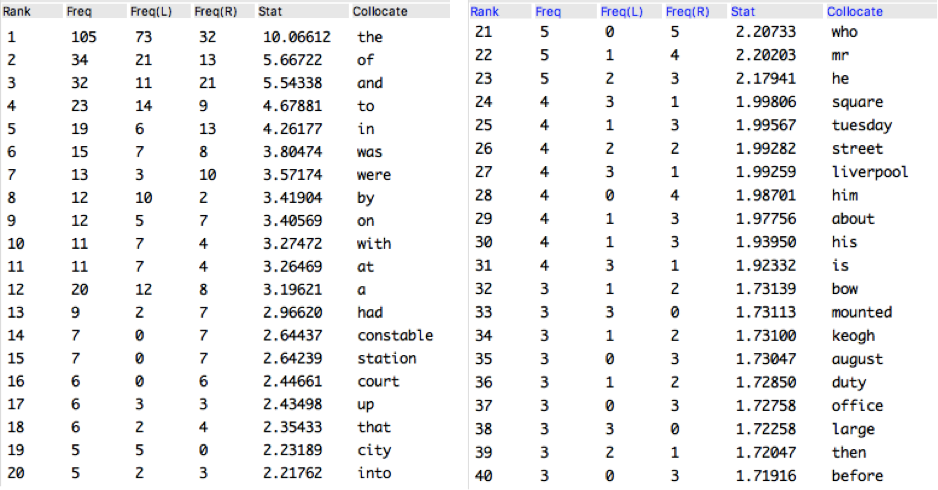
This counting is a crucial step, because humans are not impartial – we tend to notice things that interest us and/or which are unusual. This makes our intuition and ad hoc observations a poor guide for frequency. To identify the most frequent patterns of co-occurrence, there is no other option but to count. It is not that the counts are interesting in and of themselves; instead, the counts describe the evidence which will support our conclusions. Corpus linguistic tools are designed to make the identification of such words easy (see figure 3), and they often include various statistics to help make this identification sounder by taking into account the frequency of all words in the data being considered. In addition, they make it easy to switch between lists of counts and concordance lines.
This is not to say that corpus linguistics can answer all questions and solve all problems. The use of corpus linguistic methods in history poses some challenges, primarily that of lack of context. Current corpus linguistic tools offer no ways of retaining the visual characteristics of the original sources – font choices, layout, illustrations, all these are absent from the tools. In addition – and this challenge is not exclusive to corpus linguistic methods but is associated with all attempts to take into account large amounts of data – when working with large amounts of data, how do we generate, or even simply keep in mind, all of the relevant rich contextual information historians are accustomed to working with? Identifying/locating/generating important contextual information about every aspect of all these data pieces is very challenging, if not in some cases simply impossible.
Hence corpus linguistics, I suggest, could prove a useful addition to the historian’s toolkit, but by no means should it simply replace existing historical methods: in fact, it is probably most helpful in combination with other context-rich and perhaps more localised approaches. In this, as is probably the case for an increasing number of fields, I believe inter-disciplinary work holds great promise: as historians, linguists, computer scientists, and others share their experiences and approaches to tackling specific historical problems, we will surely uncover new layers of insights particularly surrounding patterns which operate across higher geographical- and time- scales than those it has previously been realistic to explore.
If I have succeeded in piquing your curiosity about corpus linguistics, you may be interested in the following links:
- Laurence Anthony’s AntConc tool, the downloadable user-friendly concordance tool which is featured in the figures of this article. (Tutorials are available here.)
- Lancaster University’s free Corpus Linguistics MOOC, which covers central corpus linguistic concepts, methods and tools as well as providing illustrations of applications to the Humanities and Social Sciences. (It does not assume prior knowledge of linguistics or corpus linguistics.)
- Steven Pumfrey’s conceptual history article on using manual and corpus linguistics approaches to explore the shift in meaning of the word ‘experiment’ from a religious to a scientific meaning in the 1660s.
- CASS’s briefing on Helen Baker’s research into the changing conceptions of poverty during the seventeenth century.